
By Siddharth Pareek (DevSecOps Centre of Excellence, Architecture & Engineering)
We’ve never had more tooling, talent, or telemetry — yet material outages persist.
For many teams, scalability and observability are now table stakes. The deeper challenge is whether systems can absorb disruption, adapt in motion, and recover without cascading harm.
According to Resilience Engineering in Practice (Hollnagel et al.), resilience is:
“The intrinsic ability of a system to adjust its functioning prior to, during, or following changes and disturbances, so that it can sustain required operations under both expected and unexpected conditions.”
In contrast, reliability is about minimising variance during normal operations. Resilience is about preserving outcomes when conditions are anything but normal.
Most modern incidents don’t stem from broken services — they arise from misaligned assumptions, fragile integrations, and drifting interfaces. A fallback removed. A retry loop is unchecked. A decision was delayed because ownership wasn’t clear.
Yet, resilience is still often treated as a post-failure concern — something tested in chaotic environments or tuned during incidents. It should be a design property embedded across architecture, contracts, and team interaction.
This article explores a model that does just that: a closed-loop approach that connects design, validation, operation, and learning — turning resilience from a fragmented concern into a shared, evolving system behaviour.

Every organisation trying to build resilient systems eventually assembles some version of the same six capabilities:
Each discipline delivers clear value. Architecture shapes system boundaries. SRE gives us metrics and thresholds. Chaos tests our assumptions. Observability provides insight. InnerSource enables scale. And customer journeys ground it all in the end-user’s reality.
The problem isn’t these capabilities — it’s how they operate: often in parallel, but rarely in sync.
Architecture teams publish patterns that often fail to reach product teams. SREs define SLOs that aren’t tied to real customer journeys. Chaos experiments run in dev, disconnected from platform learning. Observability dashboards track everything except what’s needed during failure. InnerSource efforts launch with energy, but stall without adoption.
Each lane is moving — but horizontally. What’s missing is the loop that connects them.
This isn’t a tooling gap. It’s a coordination gap, a feedback gap, and most of all, a shared accountability gap.
Incentives deepen the divide:
Until teams measure resilience as a system, local wins can still produce global fragility.
One option: align around resilience KPIs that reflect system behaviour, like:
These aren’t just metrics. They’re reflections of how tightly your six lanes are linked.
To move from fragmented excellence to systemic resilience, we’ll need more than alignment. We’ll need an operating loop — one that connects how we design, how we validate, how we operate, and how we learn.

When things go wrong in production — and they always do — it’s rarely one team’s fault. More often, it’s a gap. A missed assumption. A fragile handoff. The Resilience Architecture Integration Model (RAIM) is our attempt to close those gaps with intention.
RAIM connects six critical perspectives — Architecture, Customer Journeys, SRE, Chaos Engineering, Observability, and InnerSource — into a living loop: Design → Prove → Operate → Learn → Reuse → Design again.
It’s not a step-by-step framework or maturity ladder. It’s a circular rhythm that organisations can enter from anywhere. Some start with a fresh architecture blueprint. Others begin by making sense of a customer-impacting incident. RAIM meets you where you are — and helps you stitch those efforts together.
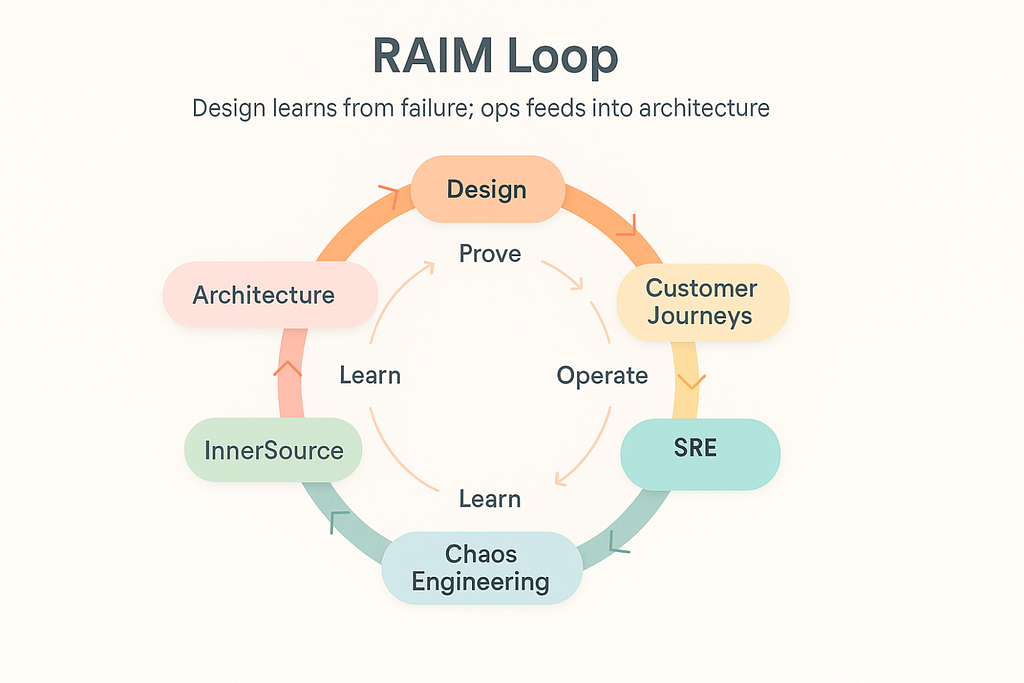
Let’s break it down, one lens at a time:
We often treat architecture like a blueprint: static, polished, abstract. But in RAIM, it’s a pressure map. Architecture is where we get honest about what’s coupled, what’s brittle, and where the real risk lies. It’s where we ask: what will fail together — and who’s going to feel it?
Architecture teams help shape failure domains, encode fallback options into infra (think: AWS zone-awareness, retry budgets), and guide whether systems default to async, bulkhead, or fail-closed patterns. Not just design for scale — but design for uncertainty.
It’s easy to say a system is “up.” It’s harder to say if a customer can complete a loan application without timeout. That’s why RAIM puts journeys at the forefront.
When an incident hits, we map the blast radius in terms of customer experience — not backend logs. Where did friction show up? What trust got broken? And when we onboard something like AWS, journey maps help us build SLOs that matter — not just monitor noise.
Resilience becomes real when it’s felt by the people using your product.
SREs in RAIM aren’t just guardians of uptime, they’re boundary keepers. They own the hard-to-navigate areas between teams, like escalation paths, mistake budget conflicts, and ambiguous dependencies.
Their job is to identify drift, reduce time-to-safety during incidents, and incorporate learnings into architecture reviews and journey design. They’re the glue that ensures no lesson stays local.
Chaos Engineering isn’t about breaking things — it’s about testing what we think is true. Does that fallback really kick in under pressure? Does our runbook hold up at 3 AM? Can two retries kill the queue?
In RAIM, chaos is focused, not random. We tie every test to something real: a recent outage, a critical path, a scary assumption. And we make sure what we learn doesn’t stay in a Slack thread.
Observability in RAIM isn’t a dashboard — it’s a narrative. Can we, within seconds, explain why a customer journey failed? Can we tell the story, not just plot the graph?
Good observability lets us debug, yes — but also helps us design smarter, prove safer, and learn faster. If we can’t see it, we can’t fix it. And if we can’t explain it, we’ll repeat it.
No team owns resilience alone. InnerSource is how we scale the wins.
When someone cracks a better way to bulkhead, that pattern should live beyond their repo. When a chaos test teaches us something new, the fallback logic should be portable. InnerSource makes that happen.
It’s how we move from heroics to habits.
The Resilience Architecture Integration Model (RAIM) is only as powerful as the teams make it. It’s not another shiny framework — it’s a working approach that earns its keep by making real problems less painful. You don’t launch RAIM like a program. You show it. In how people fix things. In who gets looped in, and in how often patterns resurface.
Most teams aren’t short on capability — they’re short on connection. You can usually spot the cracks:
We’ve all seen this. The gap isn’t tools — it’s follow-through. Feedback that stops halfway. Learning that doesn’t land. Donald Schön called these “coordination breakdowns.” RAIM starts getting traction when people trace those gaps upstream: where did this start? And who could’ve helped, if only they were in the loop?
Conway’s Law states that your system reflects your communication. That means resilience suffers when teams fail to communicate — ownership blurs. Interfaces get mushy. Dependencies spread without bounds.
RAIM pulls resilience back into architecture. Who owns what when things break? What’s async, what’s not? Where’s the blast radius supposed to stop? Good architecture makes assumptions visible — and failure, containable.
Want to dig deeper? Team Topologies (Skelton & Pais) and Site Reliability Engineering (Beyer et al.) both lay a solid groundwork.
This one’s harder. Resilience breaks when incentives pull teams in opposite directions:
We’ve seen it: teams trying their best, but no one owns the learning. And when nobody owns it, incidents repeat themselves.
This mirrors Amy Edmondson’s work on psychological safety. If learning from failure isn’t part of the culture, the org optimizes for uptime — even if it means piling up risk underneath.
You don’t “implement” RAIM. You spot it in action. The loop kicks off with something small:
Try this:
You’ll know RAIM is taking root when team language starts to shift:
This isn’t about installing new tooling. It’s about teams thinking differently.
Leaders don’t just fund resilience — they keep it going when it’s not trendy anymore, when the incidents quiet down. When teams move on.
That means:
Peter Senge refers to this as “system stewardship.” Leaders who garden the conditions, not just react to the weeds.
Most orgs already show hints of RAIM. But they’re often strong in one area and weak in the loop:
The trick isn’t to fix everything. It’s to wire input into what you already do well.
When the RAIM loop doesn’t take hold, things quietly regress:
Resilience stays local. And when real pressure hits, the system struggles to act like one.

RAIM (Resilience Architecture Integration Model) wasn’t meant to sit quietly in an engineering wiki. It’s a working model — built for motion. And that motion, over time, doesn’t just influence architecture or reduce incident rates. It starts to reshape how the entire enterprise thinks, reacts, governs, and learns.
Resilience becomes a loop, yes. But in the right hands, it becomes something bigger: a language.
Resilience today extends beyond SRE dashboards. It’s increasingly scrutinised through the lens of financial regulators, operational risk committees, and compliance partners. And that’s a good thing — because RAIM speaks their language too.
Frameworks like the FCA/PRA’s Operational Resilience rules, the Digital Operational Resilience Act (DORA) in the EU, and newer cloud concentration risk guidance all point toward a similar expectation:
RAIM doesn’t chase compliance. It earns coherence, which regulators value more than checklists. When SLOs are tied directly to essential business services, and fallback patterns are maintained as versioned architectural artefacts, audit becomes a walkthrough — not a war room.
If you’ve ever been in a post-incident review that sounded like two parallel conversations — one technical, one regulatory — you’ve felt this gap firsthand. Resilience work happens inside two loops:
These loops don’t naturally talk to each other. They often move at different speeds. And the few people who try to sit in the middle? They burn out, or get ignored.
RAIM gives those loops a shared map. When a chaos experiment uncovers a blind spot, that insight can feed a business continuity plan. When a risk team flags a critical journey, it can shape SLOs, not just sit in a PDF. The trick isn’t to slow down one loop. It’s to create feedback bridges between them — so they can move differently, but still move together.

What gets designed gets governed. What gets governed gets safer.
RAIM suggests we treat governance not as policy enforcement — but as a design exercise:
One potential future idea: a Resilience Coherence Index — measuring how tightly incidents, architecture, and compliance align. It’s less about scoring and more about surfacing blind spots before regulators do.
No version of RAIM works in a fearful culture. If raising a “what-if” makes you look like the blocker, resilience will quietly die — no matter what framework you’ve drawn.
Real resilience is evident in teams that question assumptions early, share uncomfortable learnings openly, and view failure as part of the work, not a deviation from it. That’s not idealism. It’s table stakes.
This isn’t new thinking — Amy Edmondson’s research on psychological safety laid it out years ago. However, too often, we focus on the tooling and forget the environment in which it grows. RAIM, at its best, is a system of accountability. But it needs trust to run. And trust doesn’t come from policies. It comes from people listening, following through, and making it safe to speak up.
You’ll know RAIM is taking hold when:
That’s when RAIM stops being a framework — and becomes organisational memory in motion.
RAIM isn’t the end. It’s a foundation. The next wave of work? Turning this shared loop into playbooks, literacy programs, inner-sourced patterns, and leadership workshops. It’s a systems-thinking lens for AI safety, platform governance, resilience engineering, and how regulated institutions build trust at scale.
Because in the end, RAIM isn’t about being resilient for its own sake. It’s about earning the right to move faster, serve better, and recover smarter — together.
RAIM (Resilience Architecture Integration Model) isn’t a template. It’s a lens. A way of seeing what’s already happening — and what keeps falling through the cracks. It doesn’t ask for permission to begin. It doesn’t require a playbook or a platform. It starts when one team, anywhere in the system, decides to make the invisible visible.
This is not about launching a new initiative. It’s about changing how we respond to signals — and how we treat learning — not just delivery — as the beating heart of resilience.
We’ve long relied on documentation and drills. But the future of resilience will be sensed, not scheduled. RAIM pays attention to the subtle shifts:
These aren’t big bangs. They’re quiet revolutions. Markers that the system is moving — from output to outcome, from separation to synthesis.
Every transformation has its language. DevOps gave us pipelines and CI/CD. SRE gave us SLOs and toil. RAIM now adds a new layer of shared understanding:
This isn’t jargon — it’s fluency. It allows product, platform, security, and risk teams to discuss the same system in the same room.
Resilience is no longer just technical. It’s reputational. Regulatory. Relational.
The systems we design don’t live in isolation. They shape customer outcomes, economic stability, and institutional trust. From cloud concentration risk to digital operational resilience frameworks, the message is clear: resilience isn’t optional. It’s expected.
And that expectation is shifting upstream — from operations teams to boards, from post-mortems to strategy decks.
The road from RAIM leads in different directions, depending on where you stand:
Resilience doesn’t need a charter. It needs a coalition.
RAIM is not the answer. It’s a better question.
“What would it look like if learning was the unit of resilience?”
That’s a question worth carrying into every incident review, architecture session, and leadership meeting.
Because that’s where the real loop begins.
RAIM (Resilience Architecture Integration Model) didn’t come out of thin air. It’s a result of years of working across systems, teams, incidents, and conversations — combined with lessons drawn from books, frameworks, and thinkers who’ve shaped how many of us approach resilience, architecture, and culture.
Some of what you’ve read here is my interpretation. Some of it is borrowed, reframed, or extended. This is a short acknowledgement of the sources that genuinely influenced this thinking — not as footnotes, but as foundations.
James McLeod — Head of Open Source, NatWest Group For demonstrating how InnerSource and OSPO leadership make resilience participatory — not just technical. His work at NatWest and FINOS helped shape how patterns get shared, teams learn, and feedback becomes part of everyday engineering culture.
None of this work would exist without the contributions of the above thinkers and practitioners. This is my attempt to stand on their shoulders, connect some dots, and build a bridge between technical resilience and enterprise-wide coherence
<hr><p>Resilience by Design: A New Loop for a Fragmented World was originally published in NatWest Group AI & Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.</p>