
By Greig Cowan (Head of AI & Data Science Innovation)
For many years the inclusion of AI/ML components in systems was challenging due to the many barriers that had to be overcome in terms of getting access to data, training and validating a ML model (e.g., for fraud classification), deploying and monitoring that model in production, and managing its lifecycle. This typically required specialist data science and ML teams to achieve. With the rise of Generative AI and the ease of access to frontier-level models via simple APIs, the barrier for access to AI to be built into software applications and processes has been significantly lowered. As such, it is now much simpler to add AI-driven features than ever before, using similar software engineering and DevOps practices that the industry is used to. This presents a huge opportunity for acceleration of business change.
The challenge with this new world is that the application of these powerful AI models to solve a business problem still need to be robustly and statistically validated (often called ‘evals’) in the context of the particular use case. There is simply no getting around this: validation is necessary to confirm and maintain the expected level of performance of the solution, and confidence levels need to be built around the expected bounds of behaviour (e.g., precision, recall, accuracy) for a particular business outcome. Technology teams that have traditionally not built solutions with AI/ML components may struggle to understand the risk around deployment, or the best practices and the control processes that already exist in the organisation (e.g., independent model validation) to manage that risk. The statistical nature of their behaviour makes these systems more challenging to understand, reproduce, audit, monitor and manage.
Fundamentally, this boils down to the question about what evidence we must have to know that a solution is reliably correct (i.e., performs as expected) in the context of a use case. A useful framing of the problem is given below.
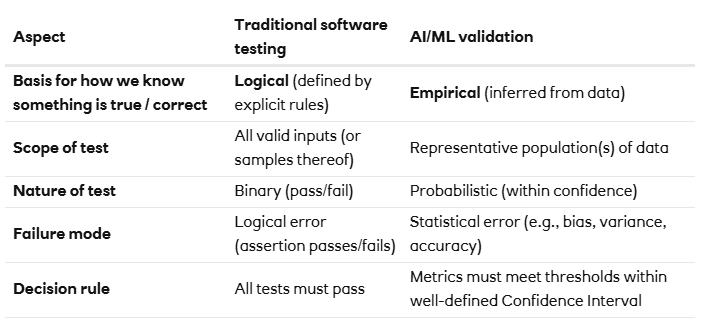
Traditional software testing is fully deterministic. We know the logical rules that must apply to determine if the software is working as expected, and it is ‘simply’ the case of running those well-defined tests across all valid inputs and evaluating pass/fail. It would be typical to only allow software to be released that passes all known tests. Working with AI/ML is fundamentally different, as the mechanism through which the correctness of the system is established is probabilistic in nature. Correctness can only be established by computing performance metrics and confidence intervals over a suitably representative sample of data as you would expect to observe when the system is used in practice. The metrics to be chosen are highly dependent on the problem (e.g., do you want to optimise for precision or recall in a financial crime detection scenario?).
An example of a ‘traditional’ software application would be a tax calculator, where the rules and logic through which tax is calculated (while being complicated) are well-defined and can be codified. The output of the calculator is always the same given the same input.
An example of a system that is driven by an ML model would be a fraud transaction monitoring system. Likely there would be a large set of well-defined and codified business rules, augmented by an ML model that had been trained to pick up patterns of fraudulent transactions from historical data features and SME-verified labels of which transactions subsequently were classified as fraudulent. The use of the model is well-defined and constrained to a particular business problem and range of outputs that it can produce.
In the case of Generative AI, an example could be a chatbot that is used to serve customer queries. The advantage of GenAI in this application is the flexibility it introduces in terms of outputs, which comes with an associated challenge of placing sufficient controls and guardrails around it to maintain performance in an enterprise setting where reliability is paramount.
Thinking about this more in terms of the software-development lifecycle, a different approach is required to perform validation of AI/ML systems, with the biggest focus being on the ability to obtain robust statistical estimates of system performance that we can trust on average, as opposed to logical test performance of pass/fail that is typical in software engineering. Importantly, the performance metrics must continue to be monitored post-deployment, as it is possible that the assumptions made during development on the distribution of input data no longer hold at some undefined point in the future (the concept of data drift).

To emphasise the point above, the basis of correctness shifts from code to data when moving from traditional software development to AI/ML model development. Data becomes both the specification and the evidence of correctness. A change in the underlying data implies that models or system prompts/context will need to be retuned and revalidated. This is particularly relevant given the introduction of the new regulation through the EU AI act etc.

Even though AI/ML systems are probabilistic in terms of us knowing their correctness, many traditional ML systems (distinct from generative systems discussed below) are deterministic when they are used to make predictions at runtime (called inference). These would typically use methods such as logistic regression or gradient-boosting to build a model of some underlying process, where the output prediction of the model is the same for a given input. This makes these systems similar to traditional software in that they are reproducible and easier to understand, audit and monitor. The table below shows the differences when building ML models, as opposed to using them to drive a particular outcome.
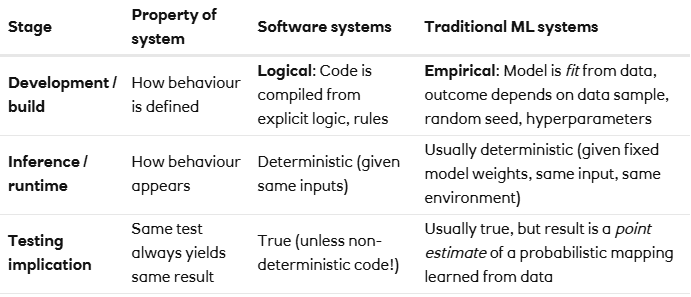
To repeat, despite traditional AI/ML inference being deterministic, our confidence in the correctness of the system is probabilistic. This is because the model is built on statistical approximations of an underlying real-world process, not on absolute logical rules. For example, we might say: “Based on the data, this prediction is expected to be correct about 95% of the time”, rather than “For input X, the output will always be Y”. Its “correctness claim” is statistical, even if the execution of the AI/ML model at runtime is not.
The introduction of Generative AI (and by extension Agentic AI) into a software application or process introduces further complexity as there is now an inherently stochastic (random) component to the output of that system given the same inputs. This is unlike traditional software development where well-defined unit tests will always pick up failure modes of the software and the same output can always be guaranteed for the same input. This remains true even in the case of LLMs with the ‘temperature’ parameter set of zero: there remains an inference-time non-determinism that cannot be controlled (technically it is possible to setup LLM inference over a GPU cluster that does guarantee deterministic outputs, but this is complex and expensive to achieve in practice). It is precisely the stochastic nature that gives LLMs their ‘magic’, as they can produce creative human-like responses to inputs, which change over time. Removing the ability to probabilistically predict the most-likely next token conditional on the input context would remove the usefulness of LLMs to solving a range of problems. This is also the cause of Generative AI models hallucinating, whereby they create seemingly convincing content that is not grounded in truth. In many use cases this is a huge benefit, but in the case of reliable and trustworthy enterprise software additional controls (e.g., human-in-the-loop) will be required. The challenge with modern Generative AI is that extremely powerful foundation models now sit behind simple and scalable APIs, significantly lowering the barrier to entry in terms of incorporating their use into software engineering. Teams building with GenAI need to be aware of the risks and the new techniques that are required to evidence correctness of their business-critical applications.
Pulling this together, the following table demonstrates how to think about different software systems according to how we know their correctness (logical versus empirical) and their behaviour at runtime (deterministic versus stochastic). We can see that traditional software applications are fully deterministic. Some randomised algorithms have a logical basis through which we know them to be correct, but are evaluated stochastically (e.g., using Monte Carlo to estimate pi, or perhaps some robotic process automation). Classical predictive ML models (and the AI systems that use them) are probabilistic in terms of how we know their correctness as the models are built/trained but are typically deterministic at runtime. Systems built using Generative AI are probabilistic in terms of how we know the underlying LLM to be correct based on its training data, and stochastic at runtime due to the inherent randomness while predicting the next token. Using generative LLMs as predictive systems moves AI assurance into the bottom-right quadrant, where both inference and validation are probabilistic. Verification of results shifts from assertion of correctness to measurement of reliability across samples. Typically, engineers building with Generative AI will not be building the foundation model themselves, but modifying their behaviour via prompt and context engineering, and fine tuning, but the validation of outputs must still be done.

If you can write assert(), you are in the logical world. If you can only estimate a confidence interval, you are in the empirical world. If the output varies per run, you are in the stochastic domain, and correctness becomes reliability under uncertainty.
How should engineering teams build AI-enabled solutions considering this non-determinism? The following table highlights the different skillsets, roles and testing mindset that is needed when building applications in each of the dimensions of correctness. Traditional software engineering teams focus primarily on the first quadrant and will likely need to build expertise when incorporating AI/ML components into new developments. Conversely, many data science teams are experts in the third (and increasingly the fourth) quadrants but need support when building robust and well-tested enterprise-ready software that is mainly based in the first quadrant, with new AI/ML modules.
The key message here is that successful experimentation and delivery will only come through fruitful collaboration between CDIO and D&A teams involving data scientists, data engineers and ML engineers. CDIO teams could also look to upskill developers in statistics (distributions, confidence intervals, and overfitting), data management, experimentation mindset and uncertainty tracking, continuous validation, monitoring and MLOps.

It is an exciting time in the world of AI, and and massive opportunity for any business to find ways to incorporate powerful AI models into new applications, processes and customer propositions. Engineering teams need to understand that while building with GenAI may feel similar to existing software development, there is a higher and more complex bar to pass in terms of evidencing how reliably correct any AI system is, data and model governance complete, and application lifecycle management. This bar becomes increasingly important as the materiality of the applications grows, which is where the value lies in any enterprise, and will only be safely and quickly achieved through strong collaboration between engineering and AI/ML teams across any organisation.
<hr><p>On the empirical and non-deterministic nature of AI systems was originally published in NatWest Group AI & Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.</p>