
By Basit Ali Saeed (Senior ML Engineer, Applied AI) and
Beth Barlow (Senior ML Engineer, AI Hub)
In Part 1, we introduced the RAG (Retrieval Augmented Generation) architecture and how we used it at NatWest Group to build a chatbot that supports our colleagues with domain-specific question answering. The system consists of two core components that contribute to the final output: the information retrieval (IR) process and the generative model.
Unlike traditional machine learning tasks where outputs are often (but not always) discriminative, evaluating text can be a challenge. Typically, ground truths are not available to work with, and choosing the right metrics to measure against isn’t always straightforward. This is further complicated in systems that have dependencies on previous steps, such as RAG-based systems. If the retrieval step finds the wrong context, do we penalise the LLM for generating the wrong answer?
In this post, we share how we built an evaluation framework that separates the components within a RAG architecture to deal with the challenges of evaluating an LLM-based system.
This section covers how we generated synthetic data and used a set of automated metrics to understand the performance of the IR and LLM response generation components.
Similar to traditional machine learning tasks, the distribution of your test set should be as close to real-world data as possible. This gives you confidence that the performance of your model in the real world will be similar to that on your test set. The same notion can be extended to natural language tasks as well; domain-specific datasets are much more likely to give an indication of model performance than general benchmarks.
Our application is designed to act as an assistant to NatWest Group employees, helping answer questions relating to internal processes. We therefore needed a test set developed in-house. Whether evaluating retrieval performance or LLM response quality, the majority of metrics require a ‘ground truth’, that is, the expected result produced by the system component. These labelled datasets are very labour-intensive to create, and at the time of testing, nothing suitable existed for our domain. We therefore decided to create a dataset comprising of synthetically generated samples ourselves.
In Part 1 of the blog, we described our hybrid search process that retrieves document chunks stored in our vector database. These chunks are designed to be contextually disparate, with the aim of improving search efficiency as well as organizing the knowledge base in a structured manner.
We can further leverage the stored chunks to create synthetic question-answer pairs. To achieve this, we fed individual chunks into an LLM, alongside instructions to produce a single question and answer using the information contained in the chunk. To ensure the balance of this overall dataset, a stratified sample (relative to the document size/number of chunks) was used to avoid over-testing on specific content.
Depending on the LLM, experimentation with the prompt is often required to generate questions of realistic tone, complexity, and brevity. There are some challenges in using this method, particularly in generating realistic questions that are highly related to the source chunk whilst introducing differences in vocabulary. To ensure a high quality final test set, we wrote data cleaning checks that included removal of questions that were duplicated, showed a high token-based similarity to their source chunk, or showed a poor semantic relevance to their source chunk. It is important to note, however, that we included questions that were deliberately noisy or vague to test the robustness of the system.
The generated answers from this process are ultimately considered ground truths against which to compare responses generated by the full RAG system.
In addition to the LLM-generated question-answer pairs, we also manually created several sets of specific question-answer pairs that weren’t associated with any of the document chunks. This was motivated by identifying specific types of questions for which we sought to improve the model’s response. For example, one set contained only ‘off-topic’ questions that were unrelated to company policies, whilst another contained vague and incoherent inputs. In both cases, the desired response is a refusal to answer. Tags were created for these targeted question types to allow us to filter the final aggregated test set and evaluate system performance across different facets. LLM-generated questions were also tagged as such for identification.
RAG-based question-answer systems require an input question, as well as a retrieved context. This context is a collection of the N most relevant chunks, and due to this, often contains noise surrounding the information required to provide the answer. Therefore, to replicate the expectations of using a RAG system, we fed the final set of test questions (synthetic and manually created) into the IR pipeline and returned N relevant chunks.
It’s also important to note that despite having no associated chunk, we nevertheless retrieved context for the manually curated questions. The reason for this is to understand whether the target output behaviour defined in the system prompt is affected by the context.
The outcome of this retrieval generation step was the creation of a dataset containing question-answer-context triplets that can be used to evaluate the RAG system.
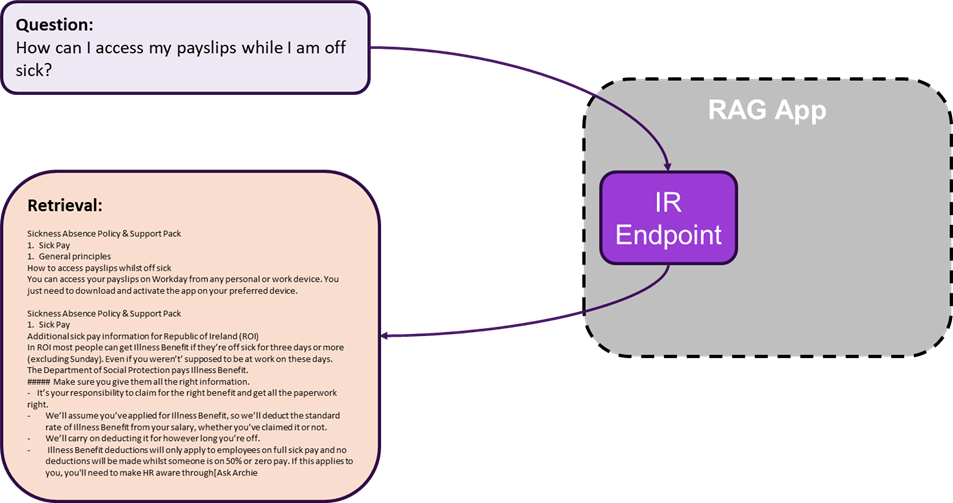
To fully optimise the IR system, having a robust setting in which to evaluate the results is essential. Generally, evaluation involves curating a test set of representative questions and results, along with assigned ‘relevance ratings’ that reflect how relevant each returned result is to the question. Such a test set can be used to calculate several key quantitative performance metrics. These include well-known machine learning metrics such as precision and recall, as well as more advanced metrics such as Mean Reciprocal Rank (MRR), which captures the position of the first relevant chunk in the results list, and Normalised Discounted Cumulative Gain, which given a graded rating scale (e.g. 0, 1, 2), captures the overall ranking order and the system’s ability to understand relative relevance.
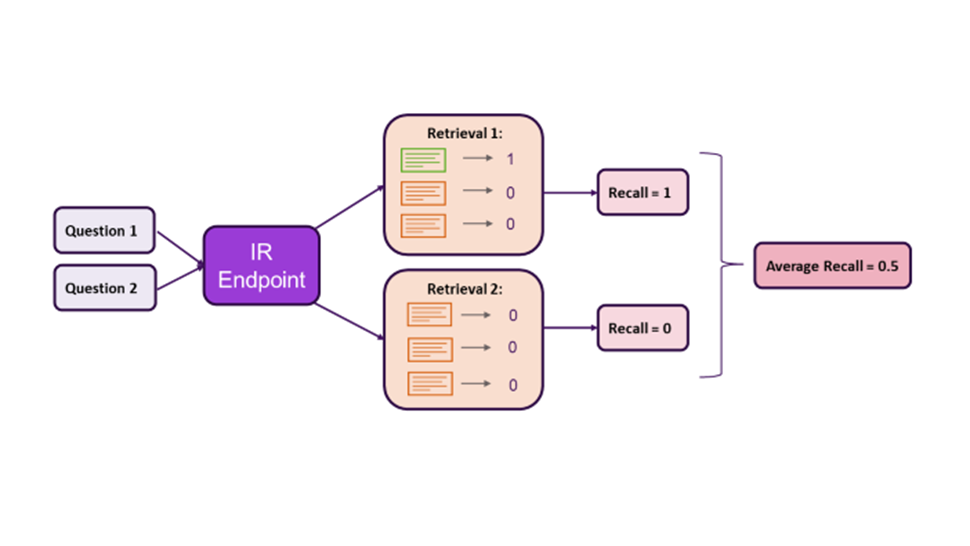
Curating a dataset with manually assigned relevance ratings requires significant manual effort and subject matter expertise. For this reason, our approach leveraged the synthetic dataset described above, comprising question-context-answer triplets. We measured retrieval performance as the ability of the system to retrieve the chunk used to generate the question. In the list of results, we considered this chunk relevant (i.e., rating 1) and all others irrelevant (i.e., rating 0). This allowed us to calculate Recall, which is the percentage of questions for which the relevant chunk is returned, and Mean Reciprocal Rank, which is a measure of the average position of the relevant chunk in the retrieval results. These metrics are intuitive and powerful. The former broadly captures the percentage of ‘correct’ contexts provided to the LLM. The latter provides a more detailed insight into the ability of the retriever to detect semantic nuances beween chunks and therefore rank results by relevance.
The evaluation pipeline is flexible and allows efficient tuning of retrieval-based hyperparameters. Two key areas of focus for us were the embedding model and the hybrid search mechanism, including number of search results and choice of re-ranking method. Our decision to use a re-ranker model was based on experiments comparing this method against popular traditional ranking mechanisms such as Reciprocal Rank Fusion and CombSUM.
For response evaluation, we leveraged the synthetic question-context-answer triplets, and this time filtered the dataset to ensure that the chunk used to generate the question-answer pair was present within the retrievals, removing all samples where this was not the case. Based on this, we can (safely) assume that the model has enough information to effectively answer the input questions.
At this stage, we have a test set that, in a traditional machine learning sense, we need to generate predictions for. This was achieved by passing a system prompt to the LLM in addition to the user prompt containing the question and context.
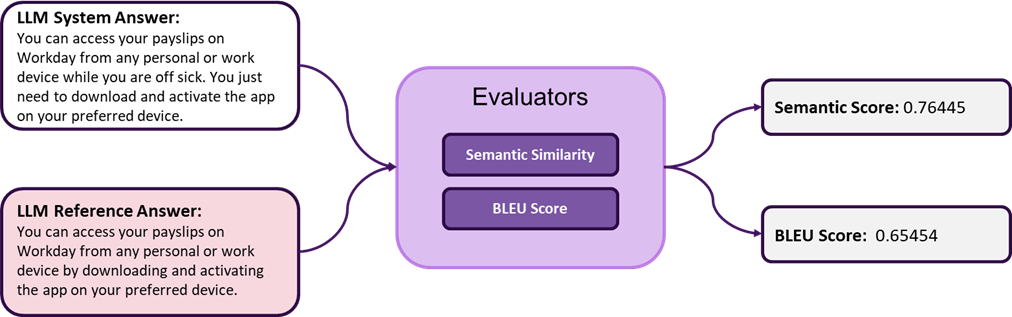
To evaluate the ‘correctness’ of the resulting responses, we measured the difference between these responses and the associated desired answers, that is, the ground truths generated from the chunk samples. Two metrics were used to achieve this:
After scoring the test set, we were able to use the question-type tags created initially to apply the two evaluation metrics to where they are more suited. These metrics allowed us to assess the performance of the system for different question types, e.g. standard questions, off-topic questions etc. and thereby hone areas of the system that are performing below expectation.
This evaluation framework is proving powerful in enabling the team to rapidly iterate and test prompts and assess how they affect performance. It’s important to note that human input isn’t entirely removed, and indeed review is often required to understand nuances, in particular ensuring that low scores are justified and align with human preference.
Manual review of questions and answers from an LLM-based chatbot is the gold-standard method of ensuring safe, accurate and consistent responses. Humans can capture nuances in LLM responses that simple string-based accuracy metrics cannot. This level of detail is crucial in order to be able to confidently promote a RAG system to a production environment with live users. In line with staged releases of our knowledge base content, a round of human evaluation was carried out prior to each release.
Unlike automated evaluation, human evaluation doesn’t require intricate creation of synthetic test sets. Instead, the purpose is to evaluate how well the system handles real user queries that are entirely representative of what the system will face in production. By nature, these questions are varied in topic, length, style, and comprehensibility, and introduce edge cases that would be extremely difficult to anticipate or mimic in a synthetic test set. This is ideal for stress-testing the developed system prompt.
To create test sets for human review, we gathered random samples of 50–100 relevant questions that had been sent to the existing pre-RAG chatbot in previous years. The questions were specific to the topic(s) that were due to go live in the upcoming release cycle. We generated context and a response for each question, to produce a dataset of question-context-answer triplets.
To gain a comprehensive view of the quality of an LLM response, we developed a series of criteria-based metrics on which to score the response. These were faithfulness, truthfulness, relevance, completeness, fluency and bias. There is no one-size-fits-all approach to selecting these metrics, and ours were motivated by industry best practices along with alignment to the system prompt instructions. Each metric was associated with a scoring rubric; a score range and supporting guidelines that were carefully written to capture the particular nuances of our chatbot use case.
An example rubric for the ‘faithfulness’ metric is as follows:
For each round of human evaluation, we recruited a team of subject matter experts with strong knowledge of the underlying content. The results were aggregated across labellers and analysed on a per-response level to understand which samples were concerning and warranted further investigation. We also calculated the aggregate agreement for each criteria-based metric to signal any disagreements that could make the results unreliable.
There are several approaches to generating test sets, which see a trade-off between manual curation effort and dataset quality.
Synthetic data has several benefits including its scalability, ability to be tailored to specific needs, and mitigating privacy concerns. However, there are a couple of downsides. Firstly, the questions generated are not entirely representative of real-life. Human-generated inputs can contain grammatical and spelling mistakes, colloquial language and a mixture of questions and statements, with it being difficult to capture this diversity by LLM-generation. Secondly, by considering the chunk from which the question was generated as the only relevant chunk, we lose a large amount of information about the overall quality of the retrieved context, in addition to the ability of the system to assess relative relevance in the ranking order.
The quality of synthetic question-answer pairs generated largely depends on the clarity of instruction within the prompt, and the LLM’s capabilities. Continued advances in the field of natural language generation lead to the possibility of creating higher quality data — specifically with models fine-tuned for this task. It therefore becomes an important avenue of further work to explore innovative approaches to synthetic data generation, in order to more accurately replicate the complex patterns and relationships in real-world data.
Alternatively, to avoid the issue in considering the source chunk as the only relevant chunk, methods exist to create real labelled test sets. The most robust method is to select a set of real user queries for which all relevant document chunks are identified in advance and can be marked by relative relevance. This dataset can be compared to the results generated by the retrieval system to calculate evaluation metrics. In doing so, we can better capture the system’s ability to order results by relative relevance, and find chunks of similar relevance from across the knowledge base. Although the dataset requires a larger up-front effort to curate, it can be augmented over time by high quality samples gathered through the production system.
The use of LLM Judges to function as proxies for labelling teams in the human review process has become increasingly common and we developed an internal re-usable package to implement the technique. In doing so, we can produce a system that achieves a similar level of scalability and efficiency as the automated evaluation explained previously, whilst maintaining a more rounded view of LLM response quality.
However, LLMs have inherent biases and using one to evaluate another may propagate that bias through the system. One of the most significant challenges we faced was engineering the LLM Judge prompts to achieve good alignment between human and LLM Judge scores. This was particularly difficult for more subjective metrics such as ‘completeness’ and ‘relevance’. These metrics are based on how a given judge interprets the question’s intent and considers which extracts in the context are relevant. In addition, we needed the judge to handle edge cases, including refusals to answer the question. We developed human-labelled benchmark test sets and used agreement metrics such as percentage agreement to ensure that our LLM Judge outputs were not skewed or showed unexpected behaviours in edge cases.
LLM-as-a-Judge is a promising method, and we are confident that with the recent rise of reasoning models and greater understanding of fine-tuning, we will be able to achieve a high level of reliability and human-alignment in future iterations.
Evaluating LLM-based systems is a complex field and there is no one-size-fits-all approach. For our RAG-based application, we employed a combination of automated metric calculation and human review to evaluate the core components of the system. Whilst human evaluation is still the gold standard, it is simply not feasible at scale with limited resources. Leveraging the automated framework above, we were able to quickly iterate on prompts and other system parameters, whilst gaining a directional understanding of how each component affects system performance.
It’s pertinent to highlight that the evaluation tooling operates outside the main RAG-based application and communicates with the RAG component via the REST API. This ensures that the system being evaluated is identical to the production solution, and permits us to experiment with greater freedom without impacting the end-user experience.
As the field of Generative AI continues to expand and we move into worlds of agent-based systems and multi-modal models, our evaluation methods will also need to evolve. This blog post introduces some important foundational techniques and we will continue to build on these as our toolkit improves with more powerful, and fine-tuned models. Keep an eye out for more posts coming later this year!
Finally, if you found our work interesting and would like to solve similar problems, we encourage you to take a look at our available job openings!
The views and opinions expressed in this article are those of the author and do not necessarily represent the views of the NatWest Group.
<hr><p>From RAG to Riches — Evaluating GenAI systems and their components was originally published in NatWest Group AI & Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.</p>